Proposed Approaches
Two different approaches to multi-task automatic synthesizer pro- gramming are presented, and a baseline was constructed to compare these methods. We find that the joint-decoder approach performs best.

Separate-Encoder Separate-Decoder (Baseline)
The baseline model uses multiple single task automatic synthesizer programming (ASP) models for a comparison to different multi-task approaches. The single task model is based on state of the art appraches to ASP based on Variational Autoencoder model[1][2].
Joint-Encoder Separate-Decoder
The Joint-Encoder Separate-Decoder approach uses n parameter decoders and n masks for each decoder to infer parameters for each synthesizer. The values of the mask are set during training to indicate which synthesizer was used to generate the ground truth audio signal. if they are all ones, the ground truth was generated by that synthesizer, so that decoder’s weights will be updated during training. if they are all zeroes then that decoder will be ignored during training. For inference, masks can be set to ones ore zeroes depending on the desired decoder’s output.
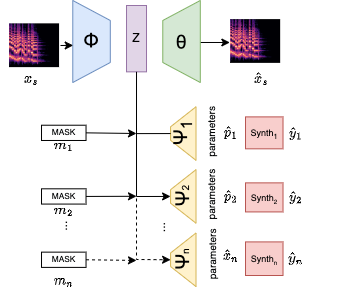
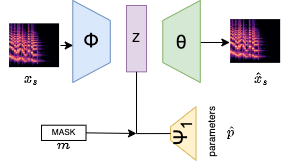
Joint-Encoder Joint-Decoder
The Joint-Encoder Joint-decoder approach attaches a single decoder to infer parameters. The dimensiality of the output parameters is the same for all synthesizer parameter vectors, so the parameter vector p is padded with zeros so that the size of the vector is always equal to size of the largest parameter vector. The dimensionality of all masks in this model are the same as well.
[1] Esling, Philippe, et al. "Flow synthesizer: Universal audio synthesizer control with normalizing flows." Applied Sciences 10.1 (2019): 302.
[2] Le Vaillant, Gwendal, Thierry Dutoit, and Sébastien Dekeyser. "Improving synthesizer programming from variational autoencoders latent space." 2021 24th International Conference on Digital Audio Effects (DAFx). IEEE, 2021.